How-to: Merging
Under development. Please contact support@catmapper.org for assistance.
1. Introduction
CatMapper helps users merge data across datasets by complex categories, like ethnicities, languages, districts, and religions. It also helps users store and share decisions they make for specific merges.
For example, a user may want to bring together:
- cultural data in the Ethnographic Atlas on more than 1000 ethnicities worldwide with
- attitude data for over 500 ethnicities from Afrobarometer attitude surveys
This requires identifying the best way to match up the ethnic categories in the Ethnographic Atlas and the Afrobarometer surveys. Manually identifying matches is challenging for a number of reasons, including differences in heirarchies, encoding, and naming across datasets.
Differences in Hierarchy
In many cases, there are direct matches, such as Tiv in Afrobarometer 9 and Tiv in the Ethnographic Atlas. However, in other cases one dataset may contain subgroups of the groups from another dataset. For example, Afrobarometer 9 uses the macro-category of Yoruba, while the Ethnographic Atlas provides information on three Yoruba sub-groups (Oyo, Ife, Ekiti, Egba). Meanwhile, Afrobarometer 9 has five finer-grained categories (Mofokeng, Mokubung, Motaung, Motloung, Motsoeneng) for the Sotho group stored in the Ethnographic Atlas.
Differences in Encoding and Naming
Even when there are direct matches between categories in different datasets, they frequently also differ in how the same categories are encoded and named. For example, Afrobarometer 9 encodes the Tiv ethnic category as Q84A = 629 and Ethnographic Atlas encodes it as society_id = Ah3. As a more complicated example, Afrobarometer 9 encodes the same Yao ethnic category with four names (Ajaua, Ciyao, Myao, and Yao) and four distinct keys (Q84A = 549, 556, 761, and 464).
CatMapper’s Solution
CatMapper provides a number of tools to assist users in overcoming these challenges. In this case, CatMapper already stores all the names and encodings of categories from Afrobarometer 9 and the Ethnographic Atlas. It also stores how categories are related, such as the Yoruba ethnic category containing subgroups Oyo, Ife, Ekiti and Egba. Using this information, CatMapper provides several functions to assist users in: (1) proposing the best way to assign categories across datasets, (2) storing thee final decisions to assign categories, and (3) sharing these decisions so users can inspect and re-use those decisions.
What if my dataset isn’t already linked to CatMapper? When a user has a new dataset whose categories haven’t yet been translated and linked to CatMapper’s categories, translating tools can assist in proposing and storing those new translations.
2. Proposing Merges
CatMapper provides several ways of proposing matches for categories from different datasets. This includes: (1) identifying only exact matches where both datasets refer to the same category (e.g. Tiv in both Afrobarometer 9 and the Ethnographic Atlas), and (2) when exact matches don’t exist, looking to closely related subgroups and supergroups for matches (e.g. matching Yoruba in Afrobarometer 9 to Oyo, Ife, Ekiti and Egba in the Ethnographic Atlas). This section walks through the key steps for proposing both exact and extended merges.
Before proposing a merge, you will need to find the CatMapper IDs for each of the datasets you would like to use. Visit the “exploring” page for help on how to find the CatMapper IDs for specific datasets. The IDs for Afrobarometer 9 and Ethnographic Atlas are SD467981 and SD14, respectively.
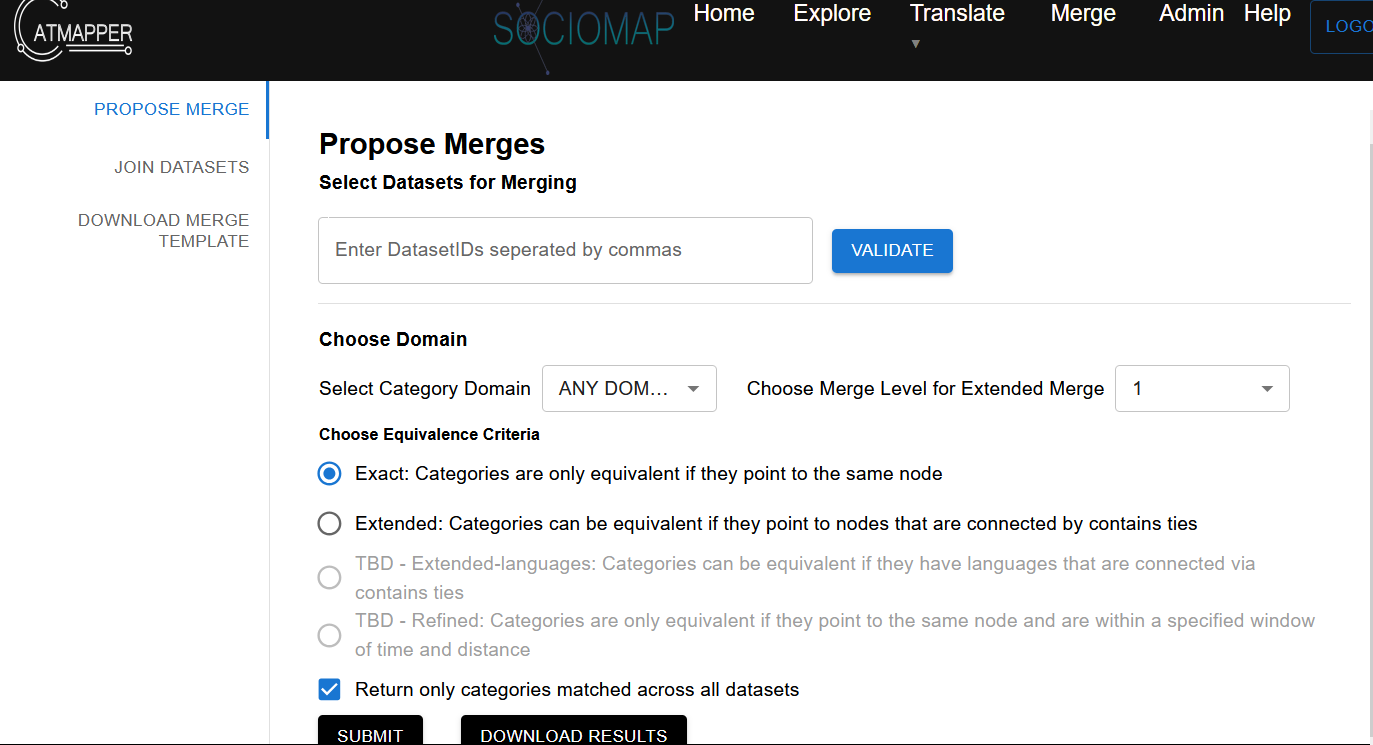
- Navigate to the Merge tab (shown above) and choose Propose Merge on the right.
- In the “Select Datasets for Merging”, type the CatMapper IDs for the relevant datasets (separated by commas).
- Click the “Validate” button and make sure it says “Validation successful”. If not, it means one of the IDs is not correct.
- Under “Select Category Domain”, choose ETHNICITY for this example. If you are proposing merges for other domains then choose the appropriate domain. For example, if you are matching districts across datasets, choose AREA.
- Choosing equivalence criteria determines how matches are made across datasets.
- The first Exact (formerly Standard) option will only propose matches between categories across datasets when they are referring to the same thing. For example, it will identify that Tiv in Afrobarometer 9 matches to Tiv in the Ethnographic Atlas.
- The second Extended option first uses the Standard option. However, if that does not identify a possible match, it then searches for other groups that are connected by contains ties in the CatMapper database. “Choose Merge Level for Extended Merge” specifies how many ties it will look through to identify a match. A merge level 1 will only look to categories that are connected by a contains tie. A merge level 2 will look for any matches up to 2 places removed in the network of contains ties.
- The third and fourth options are coming soon. Option three “Extended-languages” allows one to find matches based on similar languages associated with an ethnicity or religion.
- In “Return only categories matched across all datasets”
- Checking the box will return a spreadsheet that only contains matched categories
- Unchecking the box will return a spreadsheet that includes rows for all categories across all datasets (regardless of whether they are matched or not)
- Click the “Submit” button
- When it says “Merge proposal complete”, press “Download Results”, which will download an excel spreadsheet with the proposed matches
The merge proposal spreadsheet
The downloaded merged proposal spreadsheet provides details on how categories from different datasets are associated with each other. Each row represents a proposed match between categories from different datasets. If “Return only categories matched across dataset” was unchecked, the spreadsheet will also have many rows for categories from each dataset for which no match was found.
For an exact merge proposal, the spreadsheet includes the following columns:
CMID: The unique CatMapper ID for the category that the datasets will match on for that row
CMName: The CatMapper name for that category
Key_datasetID: For each dataset, there will be a column for the Key the datasets uses to encode that category. If there are three datasets, there will be three columns each with Key_ followed by the unique ID for that dataset.
For an extended merge proposal, the spreadsheet includes the following columns:
CMID_datasetID: For each dataset, there will be column indicating the unique CatMapper ID for the category from that dataset matched with categories from the other datasets.
CMName_datasetID: For each dataset, there will be a column with the CatMapper Name for the category from that dataset matched with categories from the other datasets.
Key_datasetID: For each dataset, there will be a column for the Key the datasets uses to encode that category.
LCA_CMID: This is the unique CatMapper ID for the least common ancestor through which a match was made. If there is an exact match, The LCA_CMID and all CMID_datasetID columns will all have the same value.
LCA_CMName: This is the unique CatMapper Name for the least common ancestor
Name_datasetID: For each dataset, there will be a column indicating the Name provided by this dataset for the category.
nTie: This is the number of ties the search had to go through to find the match. A value of 0 indicates that it is an exact match. A value of 1 indicates that the matched categories are only 1 tie away from each other. A value of 2 indicates the amtched categories are 2 ties away from each other.
Using the merge proposal spreadsheet
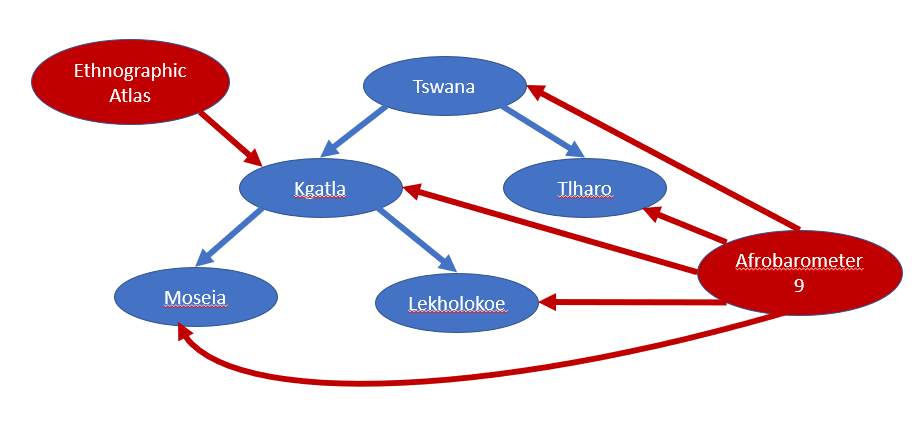
The merge proposal spreadsheet provides suggestions for how categories can be matched across datasets. In most cases, exact matches do not require any further deliberation. However, for extended matches a user must often make decisions about which matches they will ultimately use for a given analysis. For example, when using the extended merge for Afrobarometer 9 and Ethnographic Atlas, it finds an exact match between Kgatla in both datasets. However, it also finds a match between Kgatla in the Ethnographic atlas and several other related categories in Afrobarometer 9 (See figure below). These include subgroups of Kgatla (Moseia, and Lekholokoe), a parent category of Kgatla (Tswana) and a child of that parent category (Thlaro). In this case, a user who cares about only using the most closely matched categories may limit the matches to just Kgatla from Ethnographic Atlas to Kgatla and its child categories (Moseia and Lekholokoe) in AFrobarometer 9. By contrast, a user who wants to bring in more data from a larger number of categories, may match Kgatla in Ethnographic Atlas to Kgatla, Moseia, Lekholokoe, Tswana and Tlharo in Afrobaromter 9. In short, there are a number of considerations, including precision of matching and quantity of available data that may guide how users make decisions about matches based on those proposed in the merge proposal spreadsheet.
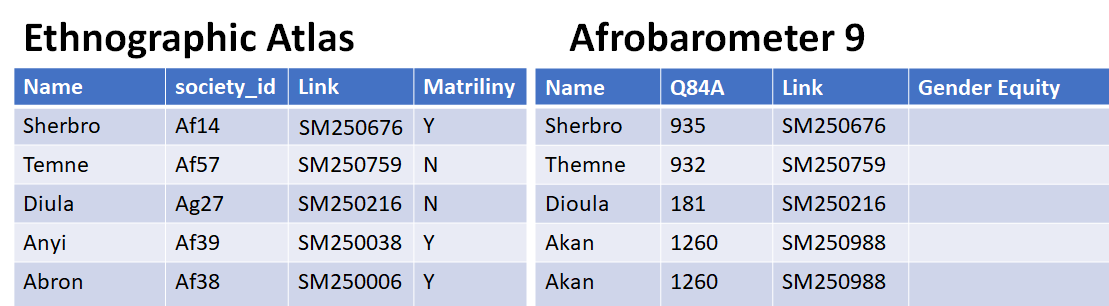
 Once a user has made their decisions about how to merge data by categories across datasets, the spreadsheet provides the necessary information to build a merge between datasets. Specifically, it includes the keys that each datasets uses to refer to corresponding categories. For example, for Tiv, the spreadsheet shows that observations in Afrobarometer 9 where the variable Q84A has value 629 would count as Tiv. Meanwhile, in the Ethnographic Atlas any rows where the variable society_id has a value Ah3 would count as Tiv. Using the spreadsheet, a user can automatically generate code that assigns a new linking variable to both the Ethnographic Atlas and Afrobarometer 9 for joining data across the two datasets by these categories. The figure below illustrates the additional link variable that would be added to permit joining the two datasets. A future tutorial will illustrate different approaches, using either native excel functions or r code, to build the code necessary to derive link variables in all relevant datasets to permit merging datasets.
Once a user has made their decisions about how to merge data by categories across datasets, the spreadsheet provides the necessary information to build a merge between datasets. Specifically, it includes the keys that each datasets uses to refer to corresponding categories. For example, for Tiv, the spreadsheet shows that observations in Afrobarometer 9 where the variable Q84A has value 629 would count as Tiv. Meanwhile, in the Ethnographic Atlas any rows where the variable society_id has a value Ah3 would count as Tiv. Using the spreadsheet, a user can automatically generate code that assigns a new linking variable to both the Ethnographic Atlas and Afrobarometer 9 for joining data across the two datasets by these categories. The figure below illustrates the additional link variable that would be added to permit joining the two datasets. A future tutorial will illustrate different approaches, using either native excel functions or r code, to build the code necessary to derive link variables in all relevant datasets to permit merging datasets.
3. Joining Datasets
Introduction
The Join Datasets tool enables users to merge two datasets that have already been translated and uploaded to the CatMapper system. Merging is based on shared CatMapper IDs (CMIDs), which link related categories across datasets. This tool will automatically identify the appropriate CMID from the Sociomap or Archamap database based on the associated Key column uploaded with the dataset. This function is useful for combining datasets that describe the same units (e.g., ethnicities, religions, or areas) but contain different types of data.
First, we will demonstrate an example of how to use the Join Datasets tool, and then we will provide a step-by-step guide for merging datasets.
Example usage
For example, you may have two datasets: GADM (download example 1) and Geonames (download example 2). They both contain information about administrative districts. Just as an example, let’s say you have a variable in GADM that measures the percentage of a population that speaks a certain language (pseudoVar1), and in Geonames, you have a variable that measures the population density of those districts (pseudoVar2). You want to merge these datasets to analyze the relationship between language prevalence and population density.
Dataset 1: GADM
| datasetID | Name | GID | pseudoVar1 |
|---|---|---|---|
| SD1 | Saint Catherine | JAM.8_1 | 0.87 |
| SD1 | Ardahan | TUR.9_1 | 0.28 |
| SD1 | Tapoa | BFA.8.5_1 | 0.02 |
| SD1 | Causeway Coast and Glens | GBR.2.4_1 | 0.33 |
| SD1 | Portland | JAM.5_1 | 1.74 |
| SD1 | Mtskheta-Mtianeti | GEO.7_1 | 1.01 |
| SD1 | West Coast | NZL.19_1 | 1.15 |
Dataset 2: Geonames
| datasetID | Name | geonameid | pseudoVar2 |
|---|---|---|---|
| SD2 | Portland | 3488997 | 1.8 |
| SD2 | Causeway Coast and Glens | 11353070 | 0.85 |
| SD2 | Saint Catherine | 3488711 | 0.49 |
| SD2 | Ardahan | 862470 | 1.46 |
| SD2 | Mtskheta-Mtianeti | 865541 | 0.41 |
| SD2 | Tapoa | 2354771 | 0.7 |
| SD2 | West Coast | 6612113 | 0.42 |
In this case, you would upload both datasets to the Join Datasets tool. The system will automatically match rows from each dataset that share the same CMID. The resulting merged file will retain all original columns from both datasets and join them by matching CMID values.
The result will look like this (table output abbreviated for space):
Merged Dataset:
| CMID | datasetID_left | datasetID_right | pseudoVar1 | pseudoVar2 |
|---|---|---|---|---|
| SM474 | SD1 | SD2 | 0.28 | 1.46 |
| SM274707 | SD1 | SD2 | 0.33 | 0.85 |
| SM2321 | SD1 | SD2 | 1.01 | 0.41 |
| SM2775 | SD1 | SD2 | 1.74 | 1.80 |
| SM2970 | SD1 | SD2 | 0.87 | 0.49 |
| SM262220 | SD1 | SD2 | 0.02 | 0.70 |
| SM3739 | SD1 | SD2 | 1.15 | 0.42 |
Step-by-Step Guide
- To use this feature, each dataset must already include:
- A datasetID column identifying the dataset (you can obtain this from the explore) section of CatMapper by searching by DATASET and then copying the CMID that is listed for that dataset. The CMID for each category will be obtained automatically from the system.
- Any original Key columns used in the translation process
The original key columns for the example datasets above are the GID and geonameid columns.
If your dataset has not yet been translated, please visit the Translate tab before continuing.
- Uploading Datasets
Navigate to the Join Datasets tab.
In the left box labeled Upload first Dataset, click Choose File and select your first translated dataset (in CSV or Excel format).
Repeat the same step on the right side in Upload second Dataset.
If you accidentally upload the wrong file, click RESET IMPORTED FILE to clear it and try again.
- Joining Datasets
Once both datasets have been uploaded: click the MERGE DATASETS button.
The system will automatically match rows from each dataset that share the same CMID.
The resulting merged file will retain all original columns from both datasets and join them by matching CMID values.
Only rows with matching CMIDs in both datasets will appear in the merged output.
- Downloading Results
After the merge is complete: click the DOWNLOAD RESULTS button to save the merged dataset to your local machine as an XSLX file.
- Notes and Troubleshooting
If either dataset is missing a datasetID column, the merge will not be possible. Please ensure you’ve used the translation tool beforehand.
The merge only works with two datasets at a time.
Merging does not currently support fuzzy or hierarchical matching–only exact CMID matches will be used.
Need help preparing your data for merging? Visit the translating section or contact support@catmapper.org.
4. Storing Merges Templates
Under development. Please contact support@catmapper.org for assistance.
6. Downloading Merging Templates
Under development. Please contact support@catmapper.org for assistance.